数据结构-哈希表

定义
「哈希表 hash table」,又称「散列表」,它通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键 key ,则可以在 O(1) 时间内获取对应的值 value 。
哈希冲突和扩容
从本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
我们可以通过扩容哈希表来减少哈希冲突。类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
「负载因子 load factor」是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表扩容至原先的 2 倍。
哈希冲突解决方案
通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一桶索引。
哈希冲突会导致查询结果错误,严重影响哈希表的可用性。为了解决该问题,每当遇到哈希冲突时,我们就进行哈希表扩容,直至冲突消失为止。此方法简单粗暴且有效,但效率太低,因为哈希表扩容需要进行大量的数据搬运与哈希值计算。为了提升效率,我们可以采用以下策略。
- 改良哈希表数据结构,使得哈希表可以在出现哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
链式地址
在原始哈希表中,每个桶仅能存储一个键值对。「链式地址 separate chaining」将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
基于链式地址实现的哈希表的操作方法发生了以下变化。
- 查询元素:输入
key,经过哈希函数得到桶索引,即可访问链表头节点,然后遍历链表并对比key以查找目标键值对。 - 添加元素:首先通过哈希函数访问链表头节点,然后将节点(键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点并将其删除。
链式地址存在以下局限性。
- 占用空间增大:链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低:因为需要线性遍历链表来查找对应元素。
值得注意的是,当链表很长时,查询效率 O(n)很差。此时可以将链表转换为“AVL 树”或“红黑树”,从而将查询操作的时间复杂度优化至 O(logn) 。
开放寻址
「开放寻址 open addressing」不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希等。
下面以线性探测为例,介绍开放寻址哈希表的工作机制。
1. 线性探测
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1 ),直至找到空桶,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素,返回
value即可;如果遇到空桶,说明目标元素不在哈希表中,返回None。
然而,线性探测容易产生“聚集现象”。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶 None ,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在。
为了解决该问题,我们可以采用「懒删除 lazy deletion」机制:它不直接从哈希表中移除元素,而是利用一个常量 TOMBSTONE 来标记这个桶。在该机制下,None 和 TOMBSTONE 都代表空桶,都可以放置键值对。但不同的是,线性探测到 TOMBSTONE 时应该继续遍历,因为其之下可能还存在键值对。
然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着 TOMBSTONE 的增加,搜索时间也会增加,因为线性探测可能需要跳过多个 TOMBSTONE 才能找到目标元素。
为此,考虑在线性探测中记录遇到的首个 TOMBSTONE 的索引,并将搜索到的目标元素与该 TOMBSTONE 交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。
2. 平方探测
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过“探测次数的平方”的步数,即 1,4,9,… 步。
平方探测主要具有以下优势。
- 平方探测通过跳过探测次数平方的距离,试图缓解线性探测的聚集效应。
- 平方探测会跳过更大的距离来寻找空位置,有助于数据分布得更加均匀。
然而,平方探测并不是完美的。
- 仍然存在聚集现象,即某些位置比其他位置更容易被占用。
- 由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问到它。
3. 多次哈希
顾名思义,多次哈希方法使用多个哈希函数 f1(x)、 f2(x)、 f3(x)、… 进行探测。
- 插入元素:若哈希函数 f1(x) 出现冲突,则尝试 f2(x) ,以此类推,直到找到空位后插入元素。
- 查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;若遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回
None。
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会带来额外的计算量。
PS:请注意,开放寻址(线性探测、平方探测和多次哈希)哈希表都存在“不能直接删除元素”的问题。
编程语言的选择
各种编程语言采取了不同的哈希表实现策略,下面举几个例子。
- Python 采用开放寻址。字典
dict使用伪随机数进行探测。 - Java 采用链式地址。自 JDK 1.8 以来,当
HashMap内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。 - Go 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
哈希算法
如果哈希冲突过于频繁,哈希表的性能则会急剧劣化。如图 6-8 所示,对于链式地址哈希表,理想情况下键值对均匀分布在各个桶中,达到最佳查询效率;最差情况下所有键值对都存储到同一个桶中,时间复杂度退化至 �(�) 。
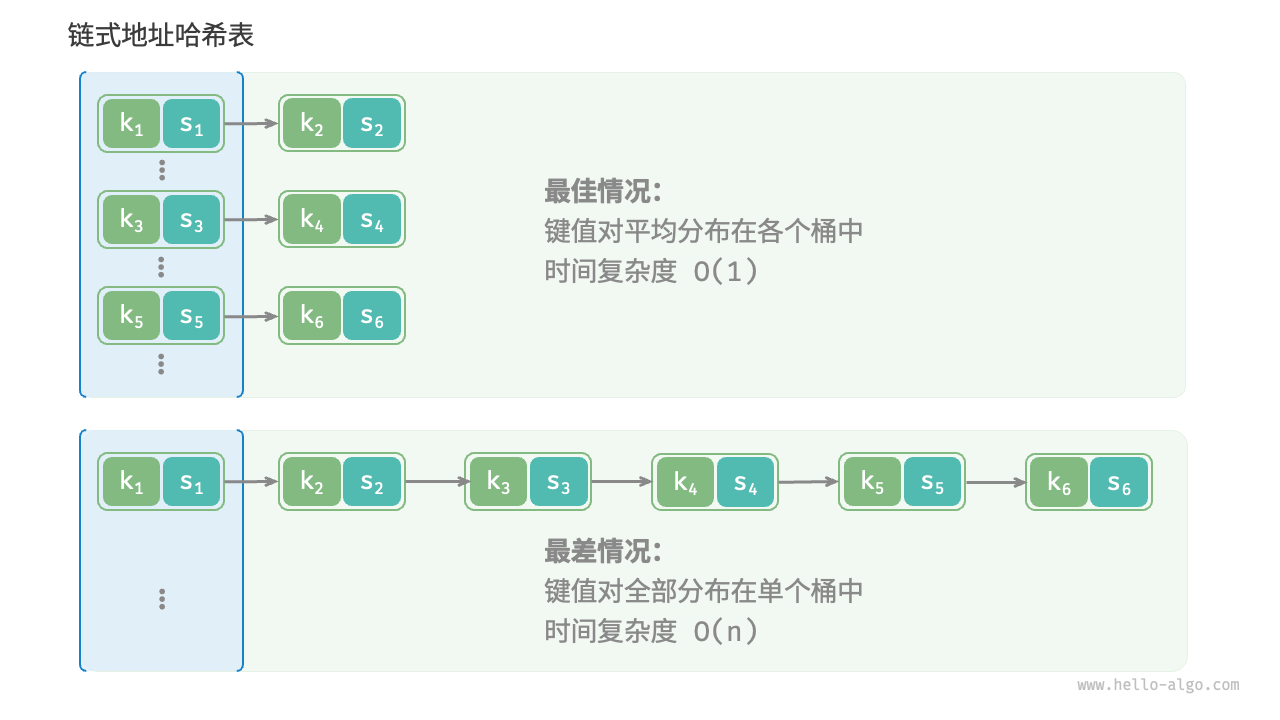
图 6-8 哈希冲突的最佳情况与最差情况
键值对的分布情况由哈希函数决定。回忆哈希函数的计算步骤,先计算哈希值,再对数组长度取模:
1 | index = hash(key) % capacity |
观察以上公式,当哈希表容量 capacity 固定时,哈希算法 hash() 决定了输出值,进而决定了键值对在哈希表中的分布情况。
这意味着,为了降低哈希冲突的发生概率,我们应当将注意力集中在哈希算法 hash() 的设计上。
哈希算法的目标
为了实现“既快又稳”的哈希表数据结构,哈希算法应具备以下特点。
- 确定性:对于相同的输入,哈希算法应始终产生相同的输出。这样才能确保哈希表是可靠的。
- 效率高:计算哈希值的过程应该足够快。计算开销越小,哈希表的实用性越高。
- 均匀分布:哈希算法应使得键值对均匀分布在哈希表中。分布越均匀,哈希冲突的概率就越低。
实际上,哈希算法除了可以用于实现哈希表,还广泛应用于其他领域中。
- 密码存储:为了保护用户密码的安全,系统通常不会直接存储用户的明文密码,而是存储密码的哈希值。当用户输入密码时,系统会对输入的密码计算哈希值,然后与存储的哈希值进行比较。如果两者匹配,那么密码就被视为正确。
- 数据完整性检查:数据发送方可以计算数据的哈希值并将其一同发送;接收方可以重新计算接收到的数据的哈希值,并与接收到的哈希值进行比较。如果两者匹配,那么数据就被视为完整。
对于密码学的相关应用,为了防止从哈希值推导出原始密码等逆向工程,哈希算法需要具备更高等级的安全特性。
- 单向性:无法通过哈希值反推出关于输入数据的任何信息。
- 抗碰撞性:应当极难找到两个不同的输入,使得它们的哈希值相同。
- 雪崩效应:输入的微小变化应当导致输出的显著且不可预测的变化。
请注意,“均匀分布”与“抗碰撞性”是两个独立的概念,满足均匀分布不一定满足抗碰撞性。例如,在随机输入 key 下,哈希函数 key % 100 可以产生均匀分布的输出。然而该哈希算法过于简单,所有后两位相等的 key 的输出都相同,因此我们可以很容易地从哈希值反推出可用的 key ,从而破解密码。
哈希算法的设计
哈希算法的设计是一个需要考虑许多因素的复杂问题。然而对于某些要求不高的场景,我们也能设计一些简单的哈希算法。
- 加法哈希:对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值。
- 乘法哈希:利用乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中。
- 异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
- 旋转哈希:将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作。
观察发现,每种哈希算法的最后一步都是对大质数 1000000007 取模,以确保哈希值在合适的范围内。值得思考的是,为什么要强调对质数取模,或者说对合数取模的弊端是什么?这是一个有趣的问题。
先抛出结论:使用大质数作为模数,可以最大化地保证哈希值的均匀分布。因为质数不与其他数字存在公约数,可以减少因取模操作而产生的周期性模式,从而避免哈希冲突。
举个例子,假设我们选择合数 9 作为模数,它可以被 3 整除,那么所有可以被 3 整除的 key 都会被映射到 0、3、6 这三个哈希值。
如果输入 key 恰好满足这种等差数列的数据分布,那么哈希值就会出现聚堆,从而加重哈希冲突。现在,假设将 modulus 替换为质数 13 ,由于 key 和 modulus 之间不存在公约数,因此输出的哈希值的均匀性会明显提升。
值得说明的是,如果能够保证 key 是随机均匀分布的,那么选择质数或者合数作为模数都可以,它们都能输出均匀分布的哈希值。而当 key 的分布存在某种周期性时,对合数取模更容易出现聚集现象。
总而言之,我们通常选取质数作为模数,并且这个质数最好足够大,以尽可能消除周期性模式,提升哈希算法的稳健性。
常见哈希算法
不难发现,以上介绍的简单哈希算法都比较“脆弱”,远远没有达到哈希算法的设计目标。例如,由于加法和异或满足交换律,因此加法哈希和异或哈希无法区分内容相同但顺序不同的字符串,这可能会加剧哈希冲突,并引起一些安全问题。
在实际中,我们通常会用一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。
近一个世纪以来,哈希算法处在不断升级与优化的过程中。一部分研究人员努力提升哈希算法的性能,另一部分研究人员和黑客则致力于寻找哈希算法的安全性问题。表 6-2 展示了在实际应用中常见的哈希算法。
- MD5 和 SHA-1 已多次被成功攻击,因此它们被各类安全应用弃用。
- SHA-2 系列中的 SHA-256 是最安全的哈希算法之一,仍未出现成功的攻击案例,因此常用在各类安全应用与协议中。
- SHA-3 相较 SHA-2 的实现开销更低、计算效率更高,但目前使用覆盖度不如 SHA-2 系列。
表 6-2 常见的哈希算法
| MD5 | SHA-1 | SHA-2 | SHA-3 | |
|---|---|---|---|---|
| 推出时间 | 1992 | 1995 | 2002 | 2008 |
| 输出长度 | 128 bit | 160 bit | 256/512 bit | 224/256/384/512 bit |
| 哈希冲突 | 较多 | 较多 | 很少 | 很少 |
| 安全等级 | 低,已被成功攻击 | 低,已被成功攻击 | 高 | 高 |
| 应用 | 已被弃用,仍用于数据完整性检查 | 已被弃用 | 加密货币交易验证、数字签名等 | 可用于替代 SHA-2 |
数据结构的哈希值
我们知道,哈希表的 key 可以是整数、小数或字符串等数据类型。编程语言通常会为这些数据类型提供内置的哈希算法,用于计算哈希表中的桶索引。以 Python 为例,我们可以调用 hash() 函数来计算各种数据类型的哈希值。
- 整数和布尔量的哈希值就是其本身。
- 浮点数和字符串的哈希值计算较为复杂,有兴趣的读者请自行学习。
- 元组的哈希值是对其中每一个元素进行哈希,然后将这些哈希值组合起来,得到单一的哈希值。
- 对象的哈希值基于其内存地址生成。通过重写对象的哈希方法,可实现基于内容生成哈希值。
在许多编程语言中,只有不可变对象才可作为哈希表的 key 。假如我们将列表(动态数组)作为 key ,当列表的内容发生变化时,它的哈希值也随之改变,我们就无法在哈希表中查询到原先的 value 了。
虽然自定义对象(比如链表节点)的成员变量是可变的,但它是可哈希的。这是因为对象的哈希值通常是基于内存地址生成的,即使对象的内容发生了变化,但它的内存地址不变,哈希值仍然是不变的。
细心的你可能发现在不同控制台中运行程序时,输出的哈希值是不同的。这是因为 Python 解释器在每次启动时,都会为字符串哈希函数加入一个随机的盐(salt)值。这种做法可以有效防止 HashDoS 攻击,提升哈希算法的安全性。